What we're working on:

Planning Data Collaboration Workflow
A bioengineering researcher studying human motor control and motor learning sought dataCoLAB input on designing a collaborative data collection workflow. One goal was to enable multiple collaborators to independently contribute data points directly to a growing dataset. The conversation with dataCoLAB consultants focused on how to make the database accessible using tools like GitHub, Open Science Framework, and to visualize the data by building a Shiny app. The consultation also considered pros and cons of having participants entering data directly into a shared dataset, versus keeping separate datasets to be integrated later.
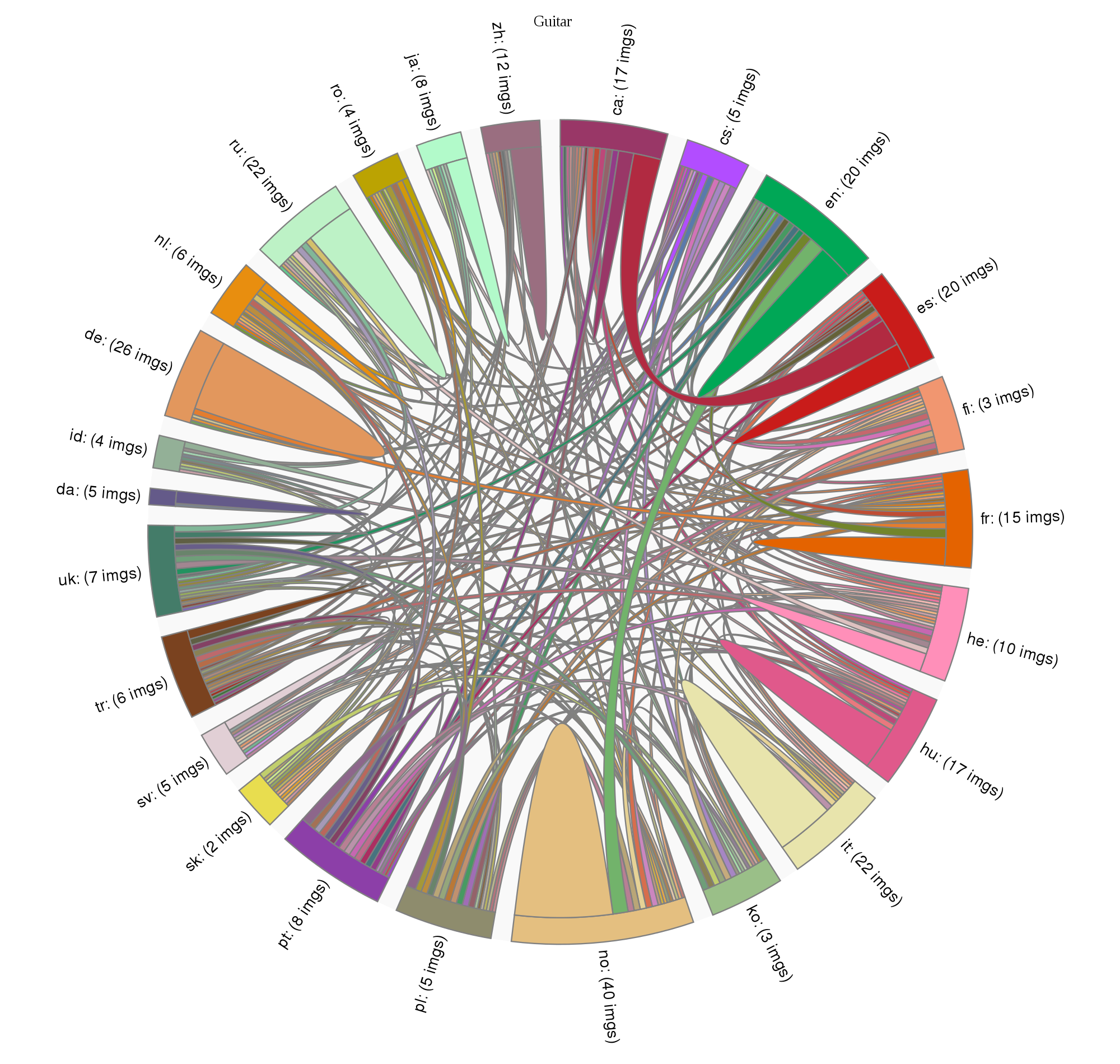
Visualization using Chord Diagrams
A researcher from the School of Nursing sought support in visualization of research data on technology use in promoting healthy behaviors among cancer survivors. When encountering problems in customizing graphs in R, the researcher suspected that the problem was in the code itself, but the dataCoLAB consultation revealed that file formatting issue were interfering with the machine readability of the data. The consultation provided guidance on how using a simple open data format from early on in the process could help avoid similar issues in future efforts.
Machine Learning to Predict Gait Intervention Outcomes
A researcher from University of Pittsburgh is examining gait intervention protocols for different demographics. In order to predict how people will respond to different types of intervention, the research relies on a database containing human demographics, training protocols, and movement outcomes. The researcher hopes to utilize machine learning to predict individual outcomes. Early consultation with dataCoLAB focused on critical aspects of data exploration to be completed prior to designing a machine learning or modeling approach. Subsequently the researcher was paired with a consultant from CMU, who is a Master's student in Data Analytics at Heinz College. The project is now in progress, and the participants will meet regularly and use Open Science Framework as a collaborative project platform.
_and_%CE%B3%E2%80%99_phase_(right)_for_a_superalloy%20cropped.png)
Text Mining to Build a Superalloy Knowledge Base
A researcher from CMU’s Materials Sciences department is interested in using text mining of journal articles and open source documents to build a knowledge base on superalloys. Key concerns include licensing constraints related to publications, and extend to techniques of text mining, including questions of focusing on full-text vs. abstract, or PDFs vs. XML. The library is in the process of helping the researcher with licensing. The researcher has been paired with a consultant from Heinz College with expertise in materials science and data analysis, and the collaboration is underway.

Analysis of Interior Design Survey Responses
A researcher from the field of architecture sought to understand how different interior designs might impact the emotion and space perception of survey subjects. In particular, the researcher wanted to learn about the impact of age and gender on the subjects’ responses to different renderings of an interior space. The initial study design leaned towards a mixed effect model, but encountered a challenge with applying an ANOVA analysis due to the distribution of the results. A dataCoLAB consultant recommended a different approach to analysis that would better fit the type of data gathered. By transformation the seven-point scale survey data into ranked scores, bias introduced by different perceptions by each participant was mitigated. The researcher found the suggestions helpful, and created a plan for implementation and follow-up.